我们都知道网络上的爬虫非常多,有对网站收录有益的,比如百度蜘蛛(Baiduspider),也有不但不遵守 robots 规则对服务器造成压力,还不能为网站带来流量的无用爬虫,比如宜搜蜘蛛(YisouSpider)(最新补充:宜搜蜘蛛已被 UC 神马搜索收购!所以本文已去掉宜搜蜘蛛的禁封!==>相关文章)。最近张戈发现 nginx 日志中出现了好多宜搜等垃圾的抓取记录,于是整理收集了网络上各种禁止垃圾蜘蛛爬站的方法,在给自己网做设置的同时,也给各位站长提供参考。
一、Apache
①、通过修改 .htaccess 文件
修改网站目录下的.htaccess,添加如下代码即可(2 种代码任选):
可用代码 (1):
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (^$|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) [NC]
RewriteRule ^(.*)$ - [F]
可用代码 (2):
SetEnvIfNoCase ^User-Agent$ .*(FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) BADBOT Order Allow,Deny Allow from all Deny from env=BADBOT
②、通过修改 httpd.conf 配置文件
找到如下类似位置,根据以下代码 新增 / 修改,然后重启 Apache 即可:
DocumentRoot /home/wwwroot/xxx
<Directory "/home/wwwroot/xxx">
SetEnvIfNoCase User-Agent ".*(FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" BADBOT
Order allow,deny
Allow from all
deny from env=BADBOT
</Directory>
二、Nginx 代码
进入到 nginx 安装目录下的 conf 目录,将如下代码保存为 agent_deny.conf
cd /usr/local/nginx/conf
vim agent_deny.conf
#禁止 Scrapy 等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#禁止指定 UA 及 UA 为空的访问
if ($http_user_agent ~* "FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}
#禁止非 GET|HEAD|POST 方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
然后,在网站相关配置中的 location / { 之后插入如下代码:
include agent_deny.conf;
如张戈博客的配置:
[marsge@Mars_Server ~]$ cat /usr/local/nginx/conf/zhangge.conf
location / {
try_files $uri $uri/ /index.php?$args;
#这个位置新增 1 行:
include agent_deny.conf;
rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;
rewrite ^/sitemap_baidu_sp.xml$ /sitemap_baidu_sp.php last;
rewrite ^/sitemap_m.xml$ /sitemap_m.php last;
保存后,执行如下命令,平滑重启 nginx 即可:
/usr/local/nginx/sbin/nginx -s reload
三、PHP 代码
将如下方法放到贴到网站入口文件 index.php 中的第一个 <?php 之后即可:
//获取 UA 信息
$ua = $_SERVER['HTTP_USER_AGENT'];
//将恶意 USER_AGENT 存入数组
$now_ua = array('FeedDemon ','BOT/0.1 (BOT for JCE)','CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot','MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control','YYSpider','jaunty','Python-urllib','lightDeckReports Bot');
//禁止空 USER_AGENT,dedecms 等主流采集程序都是空 USER_AGENT,部分 sql 注入工具也是空 USER_AGENT
if(!$ua) {
header("Content-type: text/html; charset=utf-8");
die('请勿采集本站,因为采集的站长木有小 JJ!');
}else{
foreach($now_ua as $value )
//判断是否是数组中存在的 UA
if(eregi($value,$ua)) {
header("Content-type: text/html; charset=utf-8");
die('请勿采集本站,因为采集的站长木有小 JJ!');
}
}
四、测试效果
如果是 vps,那非常简单,使用 curl -A 模拟抓取即可,比如:
模拟宜搜蜘蛛抓取:
curl -I -A 'YisouSpider' zhang.ge
模拟 UA 为空的抓取:
curl -I -A '' zhang.ge
模拟百度蜘蛛的抓取:
curl -I -A 'Baiduspider' zhang.ge
三次抓取结果截图如下:
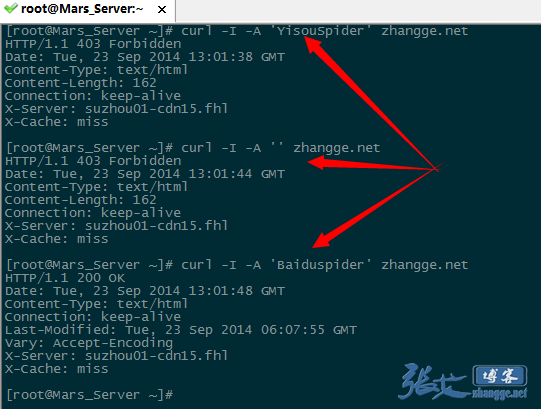
可以看出,宜搜蜘蛛和 UA 为空的返回是 403 禁止访问标识,而百度蜘蛛则成功返回 200,说明生效!
补充:第二天,查看 nginx 日志的效果截图:
①、UA 信息为空的垃圾采集被拦截:
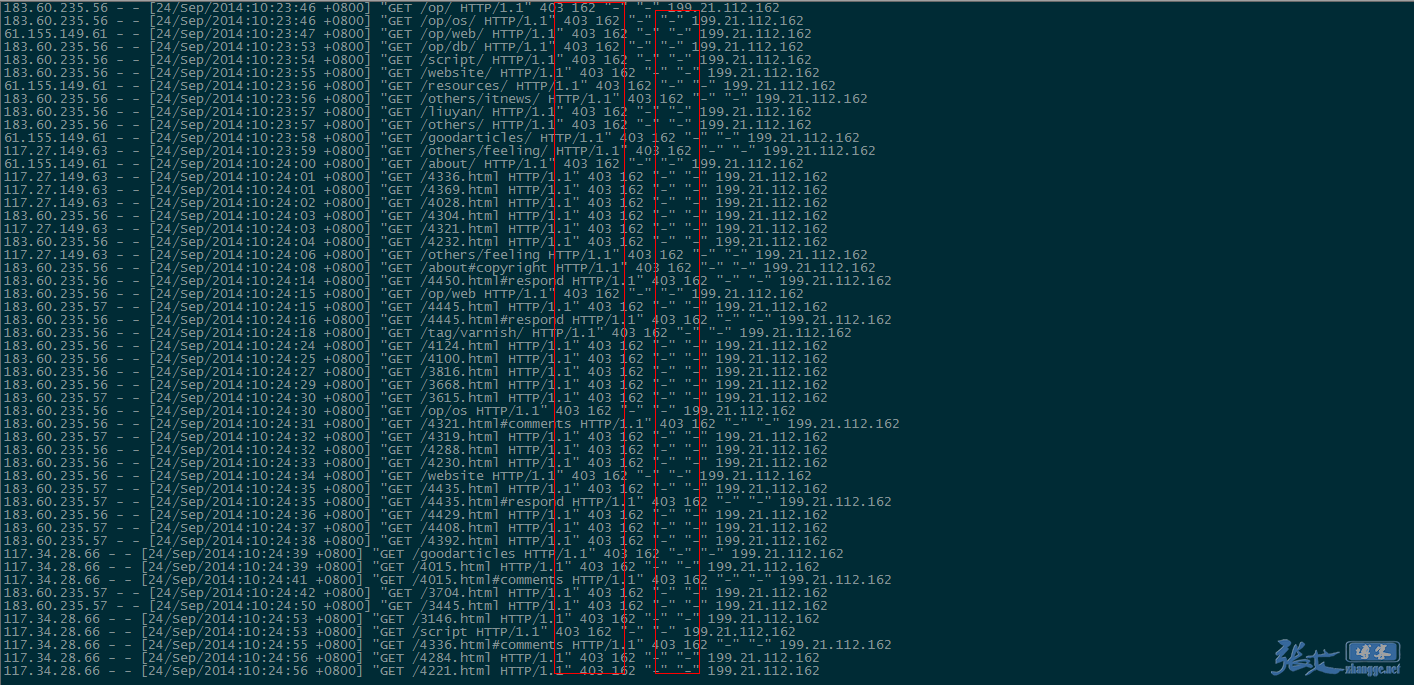
②、被禁止的 UA 被拦截:
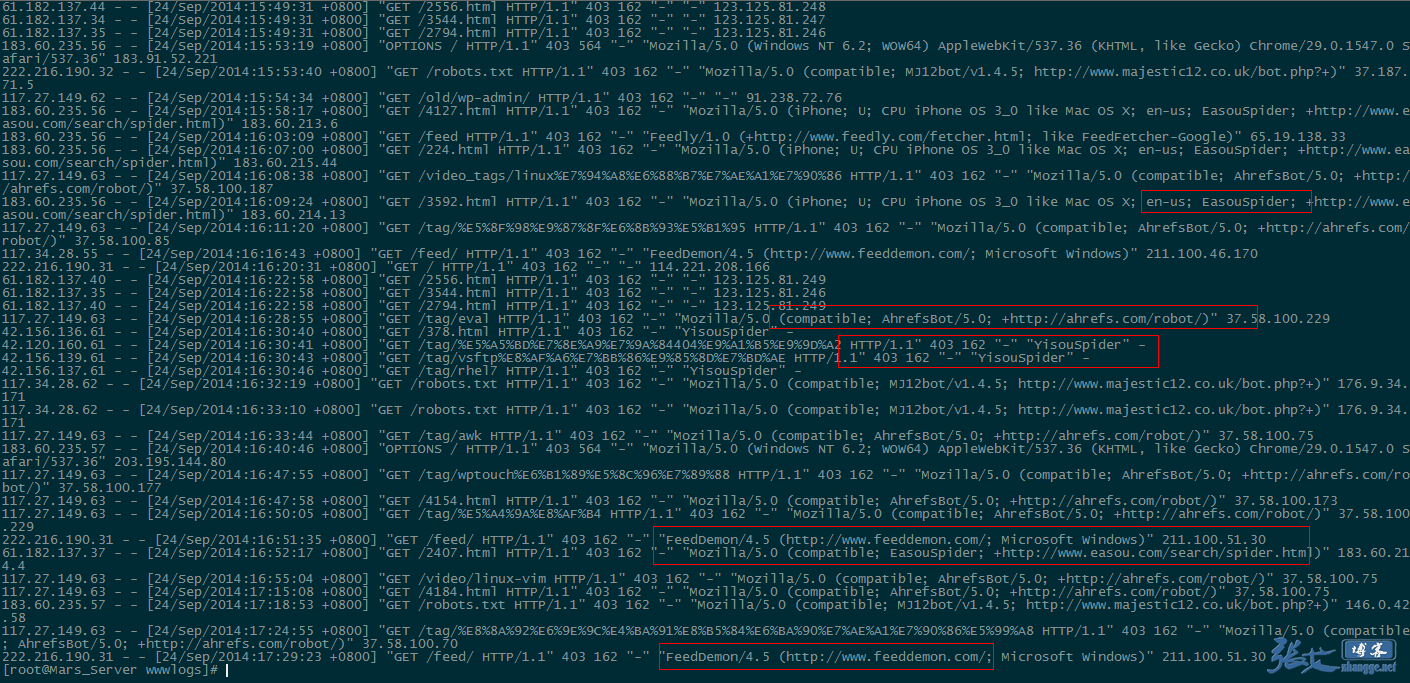
因此,对于垃圾蜘蛛的收集,我们可以通过分析网站的访问日志,找出一些没见过的的蜘蛛(spider)名称,经过查询无误之后,可以将其加入到前文代码的禁止列表当中,起到禁止抓取的作用。
五、附录:UA 收集
下面是网络上常见的垃圾 UA 列表,仅供参考,同时也欢迎你来补充。
FeedDemon 内容采集 BOT/0.1 (BOT for JCE) sql 注入 CrawlDaddy sql 注入 Java 内容采集 Jullo 内容采集 Feedly 内容采集 UniversalFeedParser 内容采集 ApacheBench cc 攻击器 Swiftbot 无用爬虫 YandexBot 无用爬虫 AhrefsBot 无用爬虫 YisouSpider 无用爬虫(已被 UC 神马搜索收购,此蜘蛛可以放开!) MJ12bot 无用爬虫 ZmEu phpmyadmin 漏洞扫描 WinHttp 采集 cc 攻击 EasouSpider 无用爬虫 HttpClient tcp 攻击 Microsoft URL Control 扫描 YYSpider 无用爬虫 jaunty wordpress 爆破扫描器 oBot 无用爬虫 Python-urllib 内容采集 Indy Library 扫描 FlightDeckReports Bot 无用爬虫 Linguee Bot 无用爬虫
六、参考资料
问说:http://www.uedsc.com/acquisition.html


我用的 DZ 3.1 也是被这些蜘蛛直接把服务费CPU100% LUIX系统 阿帕奇 如果要屏蔽是直接 在 通过修改 .htaccess文件 下面加上你上面的代码就行了吗?望回复 在线等 谢谢
嗯 可以的,具体你得弄清楚是哪些爬虫,然后加黑名单。
修改以后 打开站点.htaccess里有错误,导致现在站点打开500错误。 之前遇到一搜的爬虫 疯狂
YisouSpider 还有 majestic12.co.uk 就发现这两个 疯狂的爬 一会服务器就瘫掉了 我看您用的是 WP博客程序 之前在网上也找了一些代码 加了好像没用 我用的DZ 3.1 直接把 上面的 修改 .htaccess文件 加在最下面 就行了吧 不管他那些爬虫 除了百度和 360 谷歌 其余的都封掉 烦都烦死了
Internal Server Error
The server encountered an internal error or misconfiguration and was unable to complete your request.
Please contact the server administrator, webmaster@HA59358 and inform them of the time the error occurred, and anything you might have done that may have caused the error.
More information about this error may be available in the server error log. 出现这个。。。修改 .htaccess文件
:???: 实在搞不定就购买付费服务吧!==>付费服务
谢谢博主分享自己的经验和劳动,受益不好,再次谢过!!
多交流.
受益不好??
使用了方式3,模拟空UA,返回的竟然是500!
修改为nginx 层判断ua好使了。 谢谢张哥。
#禁止Scrapy等工具的抓取 if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) { return 403; } #禁止指定UA及UA为空的访问为什么这两个分开写?
写在一起是可以的吧?
另外,我在猎豹浏览器v5.2.9 提交评论的滑块是拉不动的,只能换到firefox下来提交了,你看看有没有什么问题。
完全可以写一起,另外没用过猎豹。。
就是chrome的修改版,你试试chrome有没有问题吧,我本机没装。
非常实用的教程,可以吧AB这类工具也给加上。
你这是多久没冒过泡了。
是很少逛博客。。。。 :mrgreen:
开启https的站点还有点问题,因为HTTP_USER_AGENT并管不着https的访问...
开启https的站点还有点问题,因为HTTP_USER_AGENT并管不着https的访问...
邮件通知审核通过,但是……??
谁说https不管useragent?用nginx去实现试试。
呃,我用的是Apache2,curl测试的确是https就不拦截了Orz
个人网站还是用Nginx舒服
最近重新折腾的时候才发现之前没有把配置写到https那个VirtualHost……折腾h2去了233
来屏蔽个百度的蜘蛛玩玩
爬虫程序不可以自己设置UA吗? 比如设置为百度的爬虫UA 。如何反这种爬虫?
把Feedly屏蔽了作甚…
博主 请教一个问题 agent 识别为 curl/7.29.0 的是什么东西 是不是抓取工具啊?
curl 是Linux下的一个命令,可以抓取可以post,很强大。
哇 博主 真热心 这么快就回复了 那我问一下 这种按你说的那不是可以用作CC攻击?如果可以大GET量请求
本来就是,变态的请求那就是攻击了。
你的VPS用的阿里云的ECS 的话 会不会被屏蔽页面啊 听说阿里云对这块拦截挺厉害的 什么 破解软件 注册机 VPN 这些东西很容易被屏蔽掉 那怎么办的?
agent:Go 1.1 package http
我算是发现了,但凡可以写爬虫的都可以 进行采集+CC攻击!
博主 Nginx日志里面 useragent 属性一般后面会跟着一个IP 那是什么 ?我发现有大量CC的攻击者 都会伪装USER agent 但是agent后面都会跟着一个IP 像这样:186.237.172.127 - - [04/Dec/2015:09:49:49 +0800] "GET /52.html?s=4415 HTTP/1.1" 500 253 "-" "Mozilla/5.0 9649" 133.130.117.212
目测是代理ip或请求IP
我用第一种方法,把代码 加入 .htaccess 后,网站访问了不了,不知道是为什么?我的网站的zencart 系统
http://www.2zzt.com/jianzhan/7347.html 这篇文章怎么这么神似 又被偷文章了 ?
呵呵了。
站长你好^^,很感谢你提供的恶意UA列表,想提一个意见看看能不能更新下呢?
1、赞同本文说法,YisouSpider现在已经成正规user agent了。
2、jikeSpider盘古搜好歹也顶着个”中国搜索”的旗号,也该也不算恶意user agent吧?
3、另外我再补充几个|Alexa Toolbar|AskTbFXTV|CoolpadWebkit|lightDeckReports Bot|DigExt|heritrix|LinkpadBot|Ezooms|^$
已去掉盘古
其实这篇文字分享的是一种方法,各位站长想增加想删除都可以自己定义。所以这些我就不加上去了,比如Alexa Tool 这个Alexa排名的工具条
nginx: [emerg] "if" directive is not allowed here in /usr/local/nginx/conf/vhost/agent_deny.conf:2
OMG 不知道什么情况
include写到哪了?
发现问题了 agent_deny.conf 不能放vhost里面 ,必须在上一层conf 下面,然后再include 就可以了。
本来就是这样啊,你自己没仔细看文章而已:
我原来是这样的:
cd /usr/local/nginx/conf/vhost
vim agent_deny.conf
include vhost/agent_deny.conf
发现不行,然后再
cd /usr/local/nginx/conf
vim agent_deny.conf
include agent_deny.conf
这样就可以了
本来就不用带全路径。
发现有BUG,在nginx上设置之后,百度站长平台检测robots.txt会提示:无法访问您网站的robots.txt文件
百度暂时无法访问您服务器上的robots.txt文件,请检查服务器的设置,确保该文件能被正常访问。错误码:403
一旦不include,再去检测就正常了
我设置过滤了ua为空的user_agent,用curl测试也成功了,但是为什么日志里返回的还都是200呢?求解
通过nginx校验cookie效果更佳。
你往index.php里调用wp_die()是逗我玩么?wp环境还没建立呢你就调用那不报错?
博主很忙,没空逗你玩。
满足恶意爬虫的访问条件才会die,没必要加载wp内核。
发现有BUG,在nginx上设置之后,百度站长平台检测robots.txt会提示:无法访问您网站的robots.txt文件
百度暂时无法访问您服务器上的robots.txt文件,请检查服务器的设置,确保该文件能被正常访问。错误码:403
把第二行代码中的Curl去掉,其他不变
http301跳转https后,抓取http时会提示返回的301,抓去https提示403,这样是否工作正常呢?
找到解决方法了,在return 301前面添加include agent_deny.conf;
学习了,谢谢
为啥.htacess的我一用就是500错误,只能使用PHP的,不知道有没有效!
张哥,
Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.3; WOW64; Trident/7.0; .NET4.0E; .NET4.0C; .NET CLR 3.5.30729; .NET CLR 2.0.50727; .NET CLR 3.0.30729) 这个ua 是不是爬虫啊。
.NET CLR 是不是用java虚拟机做的爬虫呢
张哥,
最近发现有人采集我的网站
ua>Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.3; WOW64; Trident/7.0; .NET4.0E; .NET4.0C; .NET CLR 3.5.30729; .NET CLR 2.0.50727; .NET CLR 3.0.30729)
.NET CLR 是不是指用.net做的一个爬虫程序
难道是我的姿势不对吗?
#禁止指定UA及UA为空的访问
if ($http_user_agent ~ "FeedDemon|Indy Library|....." ) {
return 403;
}
无法屏蔽,如果换成:
if ($http_user_agent ~* "FeedDemon|Indy Library|....." ) {
return 403;
}
是可以的。
你这个匹配是忽略了大小写,匹配更广一些。
感谢博主,相当有用,我用了PHP的语句,但是我的页面是HTTPS的。那么$ua = $_SERVER['HTTP_USER_AGENT'];,还有效吗,因为我发现MJ12BOT还在爬。
和https应该没关系
谢谢,现在原理我明白了,他只是屏掉,让他跳转 die('请勿采集本站,因为采集的站长木有小JJ!');
作用应该是有了,现在服务器跑起来流畅多了。
我可以说我的根目录/usr/local/nginx夏敏只有logs文件夹,根本没有conf,用的是1.1.4版本,后来换成了tengine2.2还是没找到小编说的文件,这怎么回事啊,另外试了apache的3中方法,都不行,500错误。
为什么我放进去就报这样的错误。难道是我的apache不支持这样的
通过nginx校验cookie效果更佳。
我是新手不太懂,只能搞懂第三种方法,是把内容复制进wordpress博客根目录下的index文件吗?
很全面的技术分享,谢谢