8月27日 · 2014年
Linux系统date命令无法修改或同步时间的解决办法
7800 7 7

8月13日 · 2014年
SUSE Linux系统在线安装软件命令zypper参数详解
11431 22 4

8月7日 · 2014年
Linux系统yum命令安装软件时保留(下载)rpm包
9337 17 4

7月28日 · 2014年
Linux下通过rdesktop连接Windows远程桌面
21842 15 8

7月25日 · 2014年
解决ping域名时出现“TTL传输中过期”的问题
11952 160 14

7月24日 · 2014年
Linux下用dd命令测试硬盘的读写速度
4687 14 17

7月23日 · 2014年
Linux下巧用chattr、watch命令的实例
5140 6 7

7月18日 · 2014年
Linux/SUSE安装svn客户端的问题记录
5517 6 11

7月14日 · 2014年
CentOS 7.0.1406正式版发布,附更新记录及CentOS7 iso镜像文件下载地址
19191 18 12
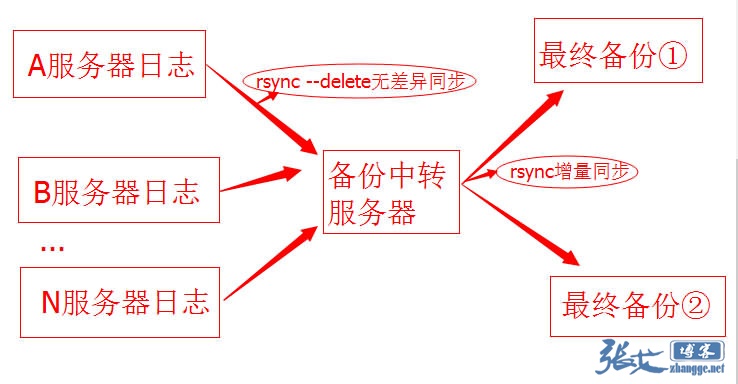
7月10日 · 2014年
服务器日志备份超节省空间的思路
1550 5 11
7月4日 · 2014年
利用Centos或RedHat的iso镜像搭建本地yum仓库
1581 5 16
6月23日 · 2014年
SecureCRT全局发送相同命令,快速抓取服务器信息的方法
10900 8 11

