SEO技巧

7月13日 · 2016年
纠正静态文件域名robots写法,解决百度搜索不显示缩略图的问题
7766 23 64

5月28日 · 2016年
WordPress百度自动推送JS优化,规避错误、重复推送问题
1374 46 114

2月11日 · 2016年
分享最近对网站外链跳转页面代码的一些改善
9174 51 142

7月31日 · 2015年
分享知更鸟Begin主题外链跳转代码,兼容下载按钮和弹出层上的外链
5665 24 15
6月1日 · 2015年
SEO分享:彻底禁止搜索引擎抓取/收录动态页面或指定路径的方法
11995 29 54
12月8日 · 2014年
百度站长平台robots工具升级后的新发现
3949 6 17
10月7日 · 2014年
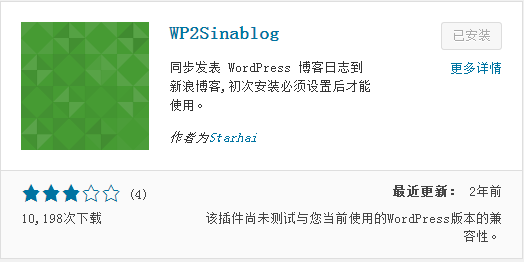
SEO养博客神器:同步文章(或摘要)到新浪博客的WordPress插件
5720 15 38
9月30日 · 2014年
SEO分享:让百度删除不想收录的域名或快照的最快方法
1574 17 9
9月24日 · 2014年
SEO分享:彻底禁止搜索引擎收录非首选域名的方法
1107 12 31
5月9日 · 2014年
另类SEO分享:利用JS封装iframe躲过搜索引擎的抓取
1692 14 60

